We often travel across the places and these journeys often teach us valuable lessons which we never want to forget. The word journey not only relates to the journeys we do across the places but it also involves the journeys we do across the time. The time is great teacher but this is partially true. The experiences that we gain during that time are the great teacher. As a part of GSoC 2013, my journey with Cassandra for the project MOST has also given me the bunch of experiences which I never want to forget.
I am specially writing this post to share the things that we did while tackling the problem - Dealing with large amount of time series based sensor data using Cassandra. I have started this article talking about the journey because dealing with any problem and finally solving the problem has many similarities with the journey. While travelling you came across the points where you have to make choice of the path from several options, It might be possible that the chosen path is not correct one or the shortest one or let say not the most feasible one. But still you consider it to be true if you reach the destination. Similarly the things we did might have other options. Some of them we discarded as we thought they were not feasible. There can be other options that we were unable to visualize at that moment. Whatever we did has laid us to the successful results.
The another reason for sharing these lessons is to find out other options that we couldn’t visualize. I request all the readers to freely share their views on the solution and help us in improving the solution. I have summarized the whole journey into few points as below.
The Design issue
While handling the large amount of data, you must take care of your database design as it affects the performance of your application.One important thing to note here is we are using NoSQL database which is non-relational and to think about the non-relational design is quite difficult as we are used to with those relational databases. You need to put your efforts in visualizing things and make sure that the design you are proposing comprises of important data items for which you have moved to NoSQL.
As in our case we found that the most critical portion of the MOST database is “data” table holding sensor measurements and the major portion of our application was dealing with this part so we decided to move it to NoSQL and we found that Cassandra is most suitable for this task. So there was only one table but the most important point was to build a design which can easily perform all those operation which are currently performed in MySQL design but with more efficiency and better performance.
In MySQL it was only one table holding relationship between datapoint and data measurements, but now in cassandra we have separate columnfamilies for each datapoint which improved the performance of operations like delete all data of particular datapoint or remove the particular datapoint.
The “Zero Row” Concept
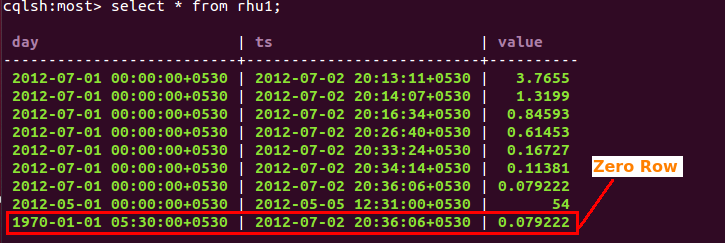
As per the requirements of our application we often need to fetch the latest value of datapoint. In Cassandra it doesn’t guarantee that the latest value will be stored at last or at first position. We are not using the Byteorder partitioner because of load balancing issues which stores the data in the order of row keys. We are using default murmur3 partitioner and as per this partitioning scheme we can not say where the latest value is stored so we decided to create separate row holding the latest value. The reason for calling it “Zero Row” is we are using first day of month (timestamp) as row key which is inserted using long value and to store latest value we used “zero” (epoch time) so we call it “zero Row”.
Write-Delete-Write technique
As I discussed in above point that we are managing the latest value in separate row, it is needed to be updated with every new write. (I know it sounds costly but as per our concern we have more read operations than write so we accepted this solution over dealing with manually load balancing in clusters while using Byteorder partitioner). So the first write is ordinary write in the column family, then we delete the old latest value and again insert the new latest value.
Sharding is important
The main purpose of sharding is to take care of your row size. The cassandra allows 2 billion columns per row and it can hold around 2 GB of data but it is advised to keep the size of row minimum. Don’t go too wide to avoid hotspots as a row never splits across nodes. So if some row is having huge amount of traffic can cause hotspot in the node.
Getting Sorted Results
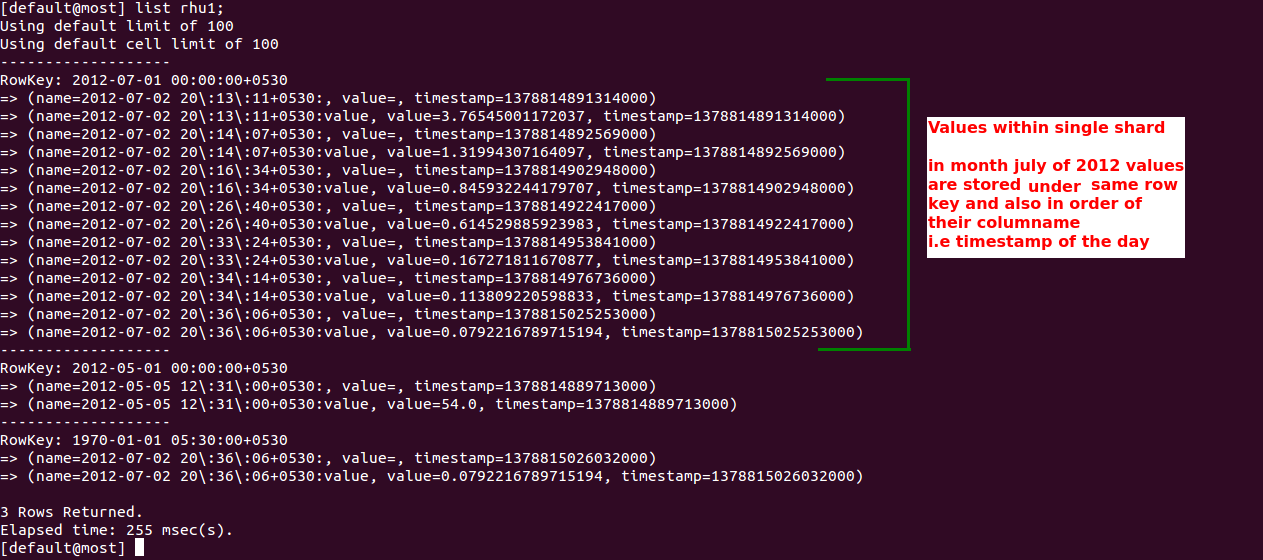
Since we have decided not to use the Byteorder Partitioner, handling such kind of operations was difficult. But we have managed to get the sorted results with the use of our row key strategy and the knowledge of storage strategy. “Cassandra stores columns in sorted manner within the Row as per the columnname.”.
Key strategy
We are using the composite key to store the data values where we store combination of first day of month and timestamp of the particular day as key. The first part act as a row key so in a single row we store the data of a month and second part i.e the timestamp act as a column keys so the data values within row are stored in order of timestamp as I said in above point.
Handling Range queries
While dealing with time-series based data, first point you come across is how to deal with the range queries? While researching over the same issue I came across many problems faced by people to handle range queries. In our case we took benefit from the native sql queries. Hopefully the CQL supports “Order By” clause but with the major limitation that it can be used only when you use IN ( same as “IN” keyword in SQL) or EQ ( Same as “=” operator in SQL) keyword in your CQL statement. Before we were using hourly based sharding but this limitation laid us to use the monthly based sharding and prepare queries in such a manner that we can use “IN” keyword along with “Order By” clause to get sorted results.
The Datastax Java Driver
Before we were using Hector API which has large community and support but the major issue is lack of proper support of native CQL queries which we needed most in our case so we moved to DataStax Java Driver with good support of Native CQL. The Java Driver is still improving and I hope more awesome features will be added to it. Thank you Datastax for being there. :)
That is all. Wait for the next article in which I am going to write about the development of the preprocessing framework of MOST project. Stay tuned and give your feedback in comments. Thanks for reading. :)